


We have already discussed what Functional Encryption is in a previous post and mentioned we are building a prototype leveraging FE to detect motion. Let’s take a look at how this is possible.
As we explained previously, FE is relatively new, and existing schemes are either relatively constrained in their function evaluation, or impractical. However, one type of FE scheme has been around for a while and is dealing with interesting beasts: vectors! We are thinking of the “Inner Product Functional Encryption Schemes”, obviously. We skipped it last time, but it might be good to start with a quick:
Math recap: inner products and vectors
Alright, first things first, what is a vector?
A vector can be different things (that are often related), but the one that interests us today is the mathematical and physical definition of a vector. (And no, it’s not just one-dimensional arrays!)
Now, an inner product is a structure that associates every pair of vectors with a scalar value. The most common inner product is the dot product, and for two vectors ![a = [a_1, a_2, \cdots, a_n]](https://s0.wp.com/latex.php?latex=a+%3D+%5Ba_1%2C+a_2%2C+%5Ccdots%2C+a_n%5D+&bg=ffffff&fg=303030&s=0&c=20201002)
![b = [b_1, b_2, \cdots, b_n]](https://s0.wp.com/latex.php?latex=b+%3D+%5Bb_1%2C+b_2%2C+%5Ccdots%2C+b_n%5D+&bg=ffffff&fg=303030&s=0&c=20201002)

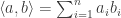
You might ask “Why care about inner products and vectors?”, well, that’s because as we stated above, we have something called “Inner Product Functional Encryption Schemes” that allows us to leverage functional encryption to compute the inner product of an encrypted vector with another given vector.
Detecting motion in a video using vectors
First, let’s start with video codecs and video encoding.
When you are recording a video and handling it on a computer, it wouldn’t be practical to have the raw data from the camera sensor. Instead videos are encoded using “codecs”, so that the video stream can be optimized in different ways. One of the most interesting ways to optimize a video stream is to compress it, in order to have smaller files (or using less bandwidth if it’s just a stream). The different codecs are using different methods to achieve this, and overall video encoding and compression is a very interesting field. But today we will focus on one standard way to do it: MPEG-4, aka H.264, one of the most used compression standard for video.
One of the main tricks used by MPEG-4 to compress video is to not redraw a full picture at each frame, instead, the video stream is split into different kinds of frames: typically the I-frames, the P-frames, the B-frames. The latter two are so-called “inter frames”, which means they are frames described in terms of their neighboring frames instead of being full frames containing all the information to redraw the picture one wants to display.

Created by Cmglee | Creative Commons license
Each frame is divided into blocks of pixels called macroblocks. The displacement between two frames of a macroblock is represented by a motion vector, and we find those motion vectors (among other information) inside the inter frames. The size of those macroblocks can vary depending on the video stream.

© copyright Blender Foundation | bigbuckbunny.com
Now that we have some representation of movement we can talk about motion detection!
Although the motion vectors represent a displacement of pixels, in most real-life scenarios it will be correlated to some kind of movement in the video. But in our case, we need to narrow a little bit which kind of movement we want to detect. We obviously wouldn’t want a wild fly wandering around to trigger the motion detection! Nor would we want the slow movement of a tree’s shadow…
We want to detect objects that are:
– Big enough
– Moving fast enough
That’s where motion vectors and macroblocks can help us. The bigger a moving object is, the greater its associated macroblock surface will be. And the faster an object goes, the greater its associated motion vector will be. To get a pretty good estimate of the “motion quantity” of an object, we could multiply motion vectors length by their associated macroblock surface. Thus both the size and speed of an object will weigh in the estimation of movement.
If we put that into equation :

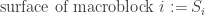
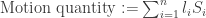
Wow, that’s pretty much the same as the inner product! By defining two vectors 


Functional Encryption
If you need a refresher, you can read our previous post on Functional Encryption.
Among the different existing FE schemes, the Inner Product family is very likely to provide us with the perfect scheme. In fact, Inner Product with Function Hiding schemes are perfectly suited to our needs! The function hiding feature allows both vectors of the inner product to remain secret, whereas in “classical” inner product schemes only one vector is kept secret.
The prototype we are working on at Kudelski Security for the FENTEC project is designed for the IoT world. The choice of a particular Function-Hiding Inner Product FE implementation will be dictated by its computational complexity. Basically, the fastest the better.
Follow us on Twitter to stay in touch with us and don’t hesitate to check on the FENTEC project if you want to know more about Functional Encryption!
