


This article is a follow-up of the excellent blog post written last year by Pascal Junod. This explains the strange title. The former post was about flaws regarding the lack of domain separation when hashing different type of data. In this new post we explore related flaws we have found in the wild regarding implementations of hash function when the result need to lie in a specific range.
Refresh on domain separation
As explained in Pascal Junod post, domain separation is a way to construct different hash function from the same primitive. It allows to avoid collision when the same hash function is used to hash different data types or structured types. For example, if someone wants to hash the array [104, 101, 108, 108, 111] they may encode it as the bytes “68656c6c6f” and pass it to the hash function. The result will collide with the hash of string “hello” or the array [6841708, 27759] which is undesirable for some application. The usage of domain separation should avoid such flaws. This problem is still regularly found in deployed solutions for example we described previously some flaws we have found during audits of io.finnet and Multisig Labs threshold cryptography implementations. More recently, another team built a private share recovery attack called TSSHOCK based on this findings.
In this post we wanted to study the dual problem. What happen if we would like to hash values to a specific range like number less than a value 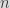
Hashing to a specific range
Some modern constructions like Identity-based, Verifiable Delay Function (VDF), e-voting, BLS digital signature or post-quantum McEliece cryptosystem need a primitive to hash a value into a specific set. This function is usually not defined in the research paper but leaves the responsibility to the implementer of choosing it properly. In addition, the construction usually assumed that the hash function has the usual properties of a standard hash function, namely, pre-image, second pre-image and collision resistances; additionally, for some constructions, the hash function should emulate a random oracle and thus outputs uniformly distributed random values.
For example the function SHA3-384 will output values which can be interpreted as integer between 0 and 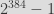

For example in Python, if we want to hash a string to a number less than 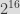
>>> import hashlib
>>> s = b"Nobody inspects the spammish repetition"
>>> int(hashlib.shake_256(s).hexdigest(2), 16)
17520
However, how to hash a value to the interval 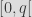
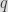
Modular bias (again)
The naive approach would be to hash the value and take the result modulo
Flawed Hunt-and-peck methods
A method similar to the rejection sampling when generating random value is called the “Hunt-and-peck” or sometimes “Try-and-Increment method”. It consists in hashing a value and if it does not fit to the desired output constraints to hash it again until a satisfying value is found. A naive implementation of such method would be:
s = b"Nobody inspects the spammish repetition"
q = 0x1a0111ea397fe69a4b1ba7b6434bacd764774b84f38512bf6730d2a0f6b0f6241eabfffeb153ffffb9feffffffffaaab
while True:
h = hashlib.sha3_384(s).digest()
h_int = int.from_bytes(h, "big")
if h_int < q:
break
s = h
print(f"hash: {h_int}")
We take the input string we hash it with SHA3-384, we transform it into an integer, we compare it with
hash: 466802949991240959638695195289112782003214451371371177487434259700090952460729664879919264417968882381626697562991
However this new function is not second pre-image resistant even though SHA3-384 is secure. Indeed, if we print all the intermediate value in the while loop we obtain:
hash: 23137220369973484377265887243569191346100483129771156387135144547456769712871740599682813528628879944752756968974946
hash: 4799338951322221704001266792102607278636860761731048000187844273144216713087340391657809976969889746113658783263501
hash: 31716994179996713780745603112864241593156066107008767210335595746891411579808647586409712124449922745051863682425891
hash: 33057019732402171167317891841094942089241481235768960620203022480520723235635591889485122017075342314445605653261792
hash: 6868136950288026075232263416539860651777920205102832818155068238833644446416649005650016224862851787880832921908269
hash: 22748065012834597045506904998237282232688457796962528509183870223455258079719138292929491465597511441781142510793740
hash: 8487665222831421746205648827090832729990406203108570795821686918493012585585156403884755993275197374472206949316440
hash: 11845129742337035831031550559334918177370659708015594781961786949561029488376363251397691522368459978971541344556850
hash: 16836971551032022124113289508056539700229076909962170679660431507603067422230552915330374164223401170221136111112554
hash: 466802949991240959638695195289112782003214451371371177487434259700090952460729664879919264417968882381626697562991
We have generated 9 different values larger than
Some variants of this approach have been used in practice. For example, in the Swiss Post e-voting system, such primitive was used. This e-vote system was tested for a real vote in 3 Swiss cantons the 18th of June 2023. All the specification and source code have been published and the security has been studied since a long time through their bug bounty program.
Here is the algorithm RecursiveHashToZq defined in the cryptographic primitives specification version 1.2.0:

Basically, The algorithm takes the input value v hashes it with the function RecursiveHashOfLength, test if the result value h is less then
Here is a simple proof-of-concept demonstrating how to obtain a second pre-image:
q = 0x5BF0A8B1457695355FB8AC404E7A79E3B1738B079C5A6D2B53C26C8228C867F799273B9C49367DF2FA5FC6C6C618EBB1ED0364055D88C2F5A7BE3DABABFACAC24867EA3EBE0CDDA10AC6CAAA7BDA35E76AAE26BCFEAF926B309E18E1C1CD16EFC54D13B5E7DFD0E43BE2B1426D5BCE6A6159949E9074F2F5781563056649F6C3A21152976591C7F772D5B56EC1AFE8D03A9E8547BC729BE95CADDBCEC6E57632160F4F91DC14DAE13C05F9C39BEFC5D98068099A50685EC322E5FD39D30B07FF1C9E2465DDE5030787FC763698DF5AE6776BF9785D84400B8B1DE306FA2D07658DE6944D8365DFF510D68470C23F9FB9BC6AB676CA3206B77869E9BDF3380470C368DF93ADCD920EF5B23A4D23EFEFDCB31961F5830DB2395DFC26130A2724E1682619277886F289E9FA88A5C5AE9BA6C9E5C43CE3EA97FEB95D0557393BED3DD0DA578A446C741B578A432F361BD5B43B7F3485AB88909C1579A0D7F4A7BBDE783641DC7FAB3AF84BC83A56CD3C3DE2DCDEA5862C9BE9F6F261D3C9CB20CE6B
v1 = b64decode("q83vASNFZ4k=")
h1 = recursive_hash_zq(q, v1)
step = 2538118759407973171811146791368667131241954935495059548630024689747655732678862557749208435969481107380814459665436536211726574891524612823116096131054900164615638966852739602583479562164823495846089556214653879414974498552902588208831350530871038078848054972266771595210321852709605285281094527904412339617311242945847373101364946953130610527817606716680070281102317872706055312245578016183191827376346092632337077166213335586307634755713948460350175685675452215190746056089690264045459643653603216880954927389434235673870858140902530600337552548992841814248314799389339609146507565655896887086919578297478830437457503474171229695140636541060083558747685412094825488085333353282723017400668288679218497723786307591379551476639363407409861045564065248885305686707532686471051481169924771998589593761370455327660724258467435909252074202410183923893361380423652361294929074328945703188531669087036325745880447022845110306798617
v2 = [step, v]
h2 = recursive_hash_zq(q, v2)
print(h1 == h2)
We chose v to be a message used in the tests of the library encoded in Base64 and the step value is an intermediate step we have found from the first computation of the hash h1 from the function recursive_hash_zq. Then, we obtained a second hash h2 from a different input [step,v] which collides with the first hash. Thus we have the same problem here as before. This problem has been reported to Swiss Post and have been patched quickly. Now, the function use a XOF to hash the value to and integer between ![[0,2^{\log_2(q)+256}]](https://s0.wp.com/latex.php?latex=%5B0%2C2%5E%7B%5Clog_2%28q%29%2B256%7D%5D+&bg=dddddd&fg=303030&s=0&c=20201002)
This problem have also be found in the Kyber Crypto Library for Go during our audit of the timelock encryption. It has been corrected with a solution described after. This is also used in the Classic McEliece public-key cryptosystem to generate a private key. In this case a 256-bit seed is used to generate the private key which is much larger. If such generation fails, the seed is hashed again until the private key is properly generated. It means that different seeds will generate the same private key at the end. However this issue have been found not harmful by the Classic McEliece team since it reduces only the entropy of the private key to 254 bits.
Non-constant time method
The previous “Hunt-and-Peck” method can be implemented in a more robust way. For example, the BLS signature uses an algorithm called MapToGroup to map a message to a point of an elliptic curve subgroup. It is defined as followed:

Basically a hash value is computed from the message M and the iteration number i until a valid point on the elliptic curve is found. Since the iteration number is concatenated with the message, this prevents a second pre-image attack as before. However, the iteration number has to be encoded on I bits otherwise the previous problem of domain separation may arise. This construction works and is proven to be secure in the random oracle model in the paper.
However, this approach is not constant time since the total number of iterations depends on the message to hash, and it may lead to timing attacks. For example, the Dragonfly handshake used by WPA3 uses this way of mapping a password to an elliptic curve point. This lead to side channel leakage of the password used to authenticate a client on a WiFi network. This is why the usage of Hunt-and-perk method is not recommended by the IETF draft.
Conclusion
Getting a uniformly distributed value in a specific range from a hash function can be tricky and often, custom solutions have flaws leading to insecure constructions. If you need to implement such methods, a constant time solution to hash value to a finite field is to use the method called hash_to_field defined in IETF draft “Hashing to Elliptic Curves”. To hash values to group of elliptic curve points the solution defined in the same IETF draft is a good option. To obtain hash results in a more complex set the MapToGroup solution with the iteration hashed together with the value is an option but this construction may suffer from timing attacks, depending on the security context.
I would like to thank Nils Amiet and Pascal Junod for their valuable comments on this blog post.
