


You have probably heard about some big announcement by Google on the topic of “quantum supremacy”, and maybe also about a rebuttal by IBM criticizing Google’s claims. And you might be wondering: “what is all the fuzz about”? With unforgivable delay, I will try here to explain what happened. But with a quirk.
You can already find pretty detailed editorials online that try to explain in accessible terms “what” happened. See for example Scott Aaronson’s pretty awesome series of blog posts. In this blog post instead, I will rather focus on the “why”.
Theory of computation and complexity is something often far from the cybersecurity community. In fact, I have met quite a few cybersecurity experts who have read and even understood (at least the basic ideas of) the Google quantum supremacy experiment, and were still wondering “why is this great? It looks unimpressive to me”. This an understandable reaction: after all, we are not going to break RSA just because of Google’s achievement, and our lives are not going to change.
But the truth is, what happened is something Big in the quantum computing field, and in this blog post I will try to explain why.
Polynomials vs Exponentials
Let’s first start with the hard math part: the difference between “polynomial growth” vs “exponential growth”. This is a concept that is probably already familiar to many readers, but let’s just recap it just in case.
In complexity theory, we talk about the “complexity” of a problem. This is a measure of the amount of resources that you need to solve such problem on a computer. It could be given in terms of different parameters, like power consumption, memory, or disk space; but usually, as a first approximation, we only look at the time cost, i.e., “milliseconds”, “hours”, or “millions of years” on a given computer. Certain problems are harder than others to solve (when running on the same hardware, otherwise we are comparing apple with oranges of course).
Then we talk about the “instance size of a problem”, or “input size”. This is a number that, roughly speaking, represents the hardness of a certain instance for a given problem. In other words: first we fix a generic mathematical problem (for example, finding a certain element in an unsorted database), and then we look at the input size (for example, the size of the database). Clearly, the larger the problem size, the harder the problem becomes. In fact, there is a correlation between the instance size and the complexity of solving that instance. For instance, one could say that the complexity of a problem 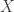
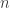

This function 

Notice that this only holds in theory or, as mathematicians say, “asymptotically”. Which means that this distinction only makes sense for very large (sometimes impossibly so) input sizes: for problems with real-world instances, a complexity of 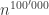
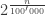
Why Polynomials?
You might wonder: “why does this distinction only make sense for polynomial functions? Why not logarithmic, or just linear, or quadratic, or double-exponential?”. This is an interesting question, but which does not have an easy answer.
A dishonest answer would be: “because in complexity theory everybody has always done so, and everybody agrees that it’s a good idea”.
A simplified answer would be: “Because of Moore’s law: the growth of computing speed we observe in real world follows an exponential trend. Which means that a problem exponentially hard will remain hard forever by just increasing linearly the input size, while a polynomially hard problem will eventually be outrun by the advancements in computing power and will eventually become easy to solve”. This explanation does not take into account that there are functions intermediate between polynomial and exponential, or the fact whether Moore’s law is bound to last or not, but it is a good enough approximation.
A more complex answer would point out that there is a correlation between polynomials and modelling of nested or parallelized computing tasks such as loops and subroutines, so that a polynomially-hard problem just represents “a combination of easy problems that remains overall easy”.
Simulating Quantum Systems
We refer to other blog posts or online resources about what a quantum computer (QC) is and how it works, but it’s generally accepted that a QC is capable (at least in theory) of incredible feats that are out of reach even for the most powerful non-quantum supercomputer – hence the interest for this rapidly evolving technology.
A less-known fact is that a QC can always be simulated by a classical computer. Yes, even on your home computer.
The way it works is, a classical computer can still run mathematical models and formulas which describe (and simulate up to a desired finite precision) any known physical system. For a QC, in particular, we can describe the full state of the qubit register using classical bitstrings, and then simulate the quantum computation by updating these bitstrings according to precise mathematical rules. So, in a sense, a classical computer can be used to do anything that a QC can do.
The problem is, this kind of simulation is usually very inefficient. There are certain particular physical systems and quantum algorithms that can be efficiently (polynomial-time) simulated, but in general the performance overhead is exponential-time (so, huge). Simulating a system of 
This overhead is, ultimately, what makes a QC so special compared to classical means, but it does not mean that a QC can always solve exponential-hard problems! This is a common misunderstanding which is sadly reiterated in many popular science articles: a QC cannot “solve a problem by checking all 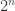
In fact, there are only a few problems that we know how to solve in polynomial-time with a QC and that we do not know how to solve in polynomial-time with a classical computer. These are mathematical problems, such as integer factorization, that are very special. The truth is, we do not know if there is a provable difference at all. There might be a way for a classical computer to solve easily these special problems just like a QC can do, but we do not know how to do it, and it seems unlikely that it is possible at all.
So far, the only way we know for doing on a classical computer anything that a QC can do is to perform a classical simulation of the whole quantum system as explained above, and this simulation is generally exponential-time hard!
Quantum Supremacy
OK, enough math, let’s get back in track with the concept of “quantum supremacy”, a term invented by physicist John Preskill in 2012. Quantum supremacy refers to a concrete demonstration of the fact that quantum computers can solve certain problems much faster than any classical supercomputer in the world. But the truth is that there is no unambiguously accepted definition of quantum supremacy. What does “much faster” mean? 100 times faster? One million times?
More important is the issue of programmability. In order for quantum supremacy to be meaningful, it is necessary to prove a quantum speedup over a broad range of problem instances, not just a single problem. This is necessary because otherwise it would be trivial to achieve quantum supremacy: we know that Nature is quantum, therefore it would be sufficient to consider a single instance of a physical process that is known to be hard to simulate classically, and that would represent a trivial counterexample of quantum-supreme system. For example, one could consider a chemical reaction between two complex molecules (actually, not even too complex) and consider the chemical parameters of the reaction as output. Then you could just define the two molecules as being a “quantum computer”, and the problem of “predicting the behaviour of that particular chemical reaction” would be a problem hard to simulate classically, but easy to solve on your particular quantum computer. Clearly, we do not want to consider these cases in our definition of quantum supremacy. In order to prove quantum supremacy, it is thus necessary that the quantum hardware we are proving is programmable, that is, able to solve a certain problem for a different range of input.
Now, this still leaves a certain degree of freedom in defining quantum supremacy. What does it ultimately mean? Do we need to break RSA-2048 in 24 hours to prove it? Is it enough to break RSA-1024? Is it enough to simulate all the possible paths in a Travelling Salesman problem with 50’000 nodes?
However, this is not super important because most of the “quantum sceptics” agree that “building a working QC is impossible” simply means “quantum supremacy cannot be achieved at all, for any possible experiment”. Are they right?
Google’s Experiment
According to Google, they are not. Google’s quantum engineers used a (programmable) 53-qubit QC to solve the following problem:
“Given a random quantum circuit (that is, made of a random sequence of gates) on 53 qubits and depth 20, predict the output distribution after the final measurement.”
The word “programmable” is, again, crucial: Google’s algorithm takes as input an (almost) arbitrary description of a quantum circuit of that size, and implements it on their QC. The output result in Google’s experiment is very noisy (basically, it’s 99.8% noise and only 0.2% the desired answer), but given that a single run of their algorithm only takes a few milliseconds, their approach is simply to repeat it thousands of times, and in a little more than 3 minutes you will get a clear enough answer to the problem.
This is by no mean a “useful” problem, but at the same time it’s not cheating. The experiment does not show that a QC can attack “everyday life” problems, but it doesn’t need to. As Scott Aaronson writes: “much like the Wright Flyer in 1903, or Enrico Fermi’s nuclear chain reaction in 1942, it only needs to prove a point”, because the main criticism against quantum supremacy is that even just a simple counterexample as the one described should be impossible.
Let us just stress again this: the main argument against quantum supremacy is that even an “artificial” problem such as the one solved by Google could never be solved by a quantum computer “significantly faster” than on a classical computer. Many physicists such as Gil Kalai hold this view. Although they are a (not so small) minority, this is unimportant, as Science is not democratic, so they might still be right.
Google’s team performed the described experiment in less than 4 minutes, while at the same time they estimated that using the fastest known supercomputer would take 10’000 years to simulate the same problem. The paper was published on Nature. If confirmed, this would have proven unambiguously that quantum supremacy had been achieved.
Not so fast, says IBM
A few days after the Google paper was published, a team of quantum scientists from IBM published a rebuttal editorial and a scientific paper, where they corrected Google’s estimates. The IBM team noticed that, if in addition to the fastest known supercomputer you can also use a large hard drive storage space, then simulating the Google problem becomes much easier, by using a time/space tradeoff technique in the simulation algorithm. IBM did not provide a proof of work or a successful simulation, but most experts agree that their methodology is sound and could be done in theory.
“Large” storage space means 250 petabytes (1 PB = 1’000’000 GB), which is huge but possible nowadays, while “much easier” means 2,5 days of computation time, according to the IBM team. Compared to the 53 qubits and 3 minutes of Google, we leave it up to the reader to decide whether this accounts for a disproval of the quantum supremacy experiment or not (as previously discussed, there is no accepted definition of when a quantum speedup becomes large enough to qualify as “quantum supremacy”).
However, the important point here is: Pandora’s box is now open. Given the exponential difficulty of simulating quantum systems, even with IBM’s new techniques, it would be sufficient for Google to extend their experiment to, say, 56 or 57 qubits rather than 53 (Google’s Bristlecone architecture is planned to scale up to 72 qubits) and this would be beyond hope of classical simulability even for all the supercomputers and storage space on Earth combined. Google is probably working on this right now.
There is also the problem of checking the correctness of Google’s experiment. This is another technical discussion that we leave to other specialized reads, but let’s just add that, on the bright side, IBM’s simulation results can actually help in proving the correctness of Google’s experiment.
We have to notice that IBM and Google are currently the main competitors in the race to the realization of a fully working quantum computer, so they are both not completely disinterested in diminishing each other’s achievements. However, it is undeniable that 1) Google’s results marked a tipping point in the faith of the scientific community in achieving quantum supremacy; and 2) at the same time, IBM’s results are a big theoretical improvement in simulating quantum systems.
What does it mean for cybersecurity?
Not much.
By now it seems that having an opinion on quantum computing has become more of a religion and less of a scientific discussion. On one side there are people desperate to sell you “the ultimate neuro-homomorphic quantum cryptography AI-powered security solution” because “quantum computers can hack you tomorrow”. On the other side there are “quantum haters” that are absolutely convinced that QC is a scam that will never work – both parties having often zero scientific background in quantum information theory but, hey, who needs to be an expert in 2019 in order to have an authoritative opinion?
For those people who believe in quantum computing, Google’s experiment is just another proof of the undeniable trend which is going on since a few years already.
For the haters, Google’s experiment doesn’t prove anything / must be wrong / is overhyped.
And then in between there is the rational scientific discussion, which is still ongoing, and is producing a richness of results unseen in most technological disciplines, and leading us to an exciting future of discoveries – be them in QC proper or just in quantum simulation.
From the point of view of security, the whole Google vs IBM business is just a remarkable proof of how much interest is moving in the direction of quantum computing. Google’s results do not lead us any closer to breaking RSA than we were before. At the same time, it shows that technology is improving despite denials, and as such it is getting us closer and closer to a point where we will use quantum computing power for real-world problems, including security.
But if your question is rather “OK, but when do I have to start worrying about quantum computers?” then the answer is much easier: yesterday.
