


In this post, we discover a strange creature named Modulo Bias, learn how it is born, why it is so dangerous, and how to fight it.
The perpetual finding
Over the last 3 years, I’ve worked on countless code reviews and if there is one vulnerability that I keep seeing over and over again, that’s definitively the modulo bias. For example, I was recently working on an audit, and did a simple search on the modulo operator in the the code base, which gave me 3 results… Well, guess what? Two of them were introducing a modulo bias, but these were in test files, which is arguably not a problem per se. But the last one was introducing an actual modulo bias which could undermine the trust one would place in the said code base because it produced biased results. I am not going to say that 100% of the modulo operations I’m seeing are introducing modulo biases, but they do way too often.
Sadly, every time I wanted to send a link to someone to explain it clearly, as well as how to avoid it, I’m finding myself looking around on the internet to no avail. The scarcity of the documentation on the topic remains surprising to me, especially when thinking about how many times I’ve heard about modulo bias and seen it in the wild.
As we will see, the big problem with modulo biases is that they can allow you to recover private keys for certain schemes, including the ones used in Bitcoin, Ethereum and many other blockchains, or by manufacturers to sign their firmwares!
So, let’s do this:
A modulo?
First things first, we need to discuss what is a modulo. The modulo operation is used a lot in Cryptography, since we are usually dealing with number theory and algebraic structures that rely on the modulo operation at their core. But it is also used more broadly in Computer Science. It is typically represented in code by the symbol % and it is a binary operator that will take two integers as input and give one integer as output. The modulo as we know it in code is computing the remainder of the division of an integer a when divided by an integer b. That is: 

a%b == r, which we read “a modulo b is equal to r“, where r is the rest of the division of a by b.
Truth to be told, the modulo as defined in mathematics is an equivalence relation defined over the ring of the integers and it says two integers 

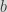

What is telling about modulo, and showing how fundamental they are in Computer Science, is that they are defined on page 39 of Donald E. Knuth’s “Fundamental Algorithms” (3rd Edition), the first volume of “The Art Of Computer Programming”. There, it is defined using the notion of “floor” and “division”, which together form the so-called “integer division” we have in programming. Specifically it is defined as follow:
If
Donald E. Knuth in “Fundamental Algorithms”and
are any real numbers, we defined the following binary operation:

A bias?
So what does it mean, a modulo bias? Well, the problem appears when you have to pick at random an integer, usually you want to pick the integer in a given range, but you want the integer to be uniformly distributed within the given range. For example, if your range is [0, 106], you’d like all values between 0 and 106 inclusive to be as likely as each other, with the probability of getting any of the 107 values ![x \in [0, 106]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C+106%5D&bg=dddddd&fg=303030&s=0&c=20201002)

GetRandom, or on /dev/urandom, which both will provide you with a set number of random bytes. So in this example, it would suffice to sample at random 1 byte, since with 8 bits you can represent 255 values. But then you need a way to constrain your random byte to only the values 0 to 106, and that is typically where the modulo is misused and causing a Modulo Bias: your random byte, once casted to an integer will have a value between 0 and 255, thus one might be tempted to take its value modulo 107, because then you are guaranteed to obtain a value in the range 0 to 106, since 107 would be mapped to 0, 108 to 1, etc.
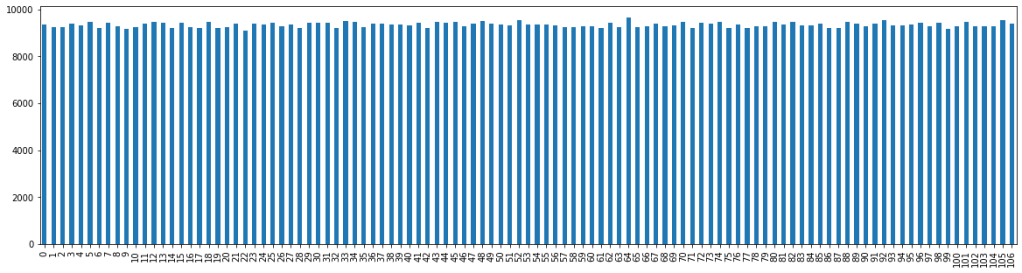
Let’s use Python with the Pandas library to retrieve 1’000’000 values from the operating system RNG, and show the value distribution :
import pandas
import os
s = pandas.DataFrame({'value':list(os.urandom(1000000))})
s['value'].value_counts().sort_index().plot(figsize=(20,5),kind='bar')

These values look evenly distributed across the 255 possible values, which is expected from the random number generator. What about the distribution of random values modulo 107?
import pandas
import os
s = pandas.DataFrame({'value':[x%107 for x in os.urandom(1000000)]})
s['value'].value_counts().sort_index().plot(figsize=(20,5),kind='bar')

And you can see that the modulo introduced a bias on the lowest 42 values! Why these values? Well, simply because the random value is initially sampled between 0 and 255, since we are taking 1 byte of random data. So all values from 0 to 213 are getting mapped to the range ![[0, 106]](https://s0.wp.com/latex.php?latex=%5B0%2C+106%5D&bg=dddddd&fg=303030&s=0&c=20201002)

![[0, 41]](https://s0.wp.com/latex.php?latex=%5B0%2C+41%5D&bg=dddddd&fg=303030&s=0&c=20201002)
![[42, 106]](https://s0.wp.com/latex.php?latex=%5B42%2C+106%5D&bg=dddddd&fg=303030&s=0&c=20201002)
The problem is basically the same as when you’re cutting a rope into smaller pieces of a given size: the last piece will most likely not be of the same size as the others, except if the initial length of your rope was perfectly divided by the length of the pieces.
The dangers of such biases
Now, the value we sampled at first was random and we reduced it modulo something, but in the end the result still remains random… Sure, the 42 first values were more probable, but do we really need a perfectly uniform distribution of our random values? You would still have a hard time predicting the result of the reduction of a random 32 byte integer modulo a 128bit integer, since there are just too many possibilities, wouldn’t you think?
Well, yes and no! Yes, one wouldn’t be able to predict it, and yes, if you were to generate a nonce using this method, your nonce still has a overwhelming chance of being unique.
But NO! You shouldn’t rely on these claims, because even 1 bit of bias on a 256 bit nonce value can be enough to attack certain cryptographic schemes!
In general, biases are extremely dangerous for the following (somewhat related) schemes:
- the (EC)DSA signature scheme requires uniformly distributed nonces for its
value, and attacks exploiting biased nonce have been known since 1999, and since have been used in practice multiple times for ECDSA (the infamous PS3 hack, Biased Nonce Sense, etc.)
- the ElGamal signature schemes in general (which was behind a vulnerability in GnuPG)
- the Schnorr signature schemes in general (just like the others)
For instance, the recent LadderLeak paper presents a private-key recovery attack against ECDSA “with less than 1 bit of nonce leakage”, which basically means a leakage that has some chances of occurring, and guess what? A non-uniform distribution can be seen as a leakage: in our example, the lower 5 bits have a higher chance of being set than the rest. Yes, you’ve read this correctly: if any bit of the nonce is somewhat predicable you can break (EC)DSA, provided you can collect enough biased signatures.
The attacks targeting these schemes are usually relying on the Hidden Number Problem (HNP, which was already introduced at Crypto ‘86 over 33 years ago) and is often solved using lattice representations in which one can then solve the closest (or shortest) vector problem to obtain solutions, or statistical attacks such as the Bleichenbacher one using FFT. The idea behind these attacks are that you have a nonce leakage, which you can exploit by collecting enough “leaky signature” (notice that a modulo bias can be seen as a probabilistic leak of the value of certain bits) to construct a Hidden Number Problem whose solution usually allows you to recover the private key used in the scheme. This the worst case possible for a public key scheme. (Interestingly, other schemes such as Pedersen commitments are not sensitive to modulo bias because they do not rely on reusing a private key.) Notice that these attacks can be carried out in the same way if you were to obtain a side-channel leakage that allows you to gain some information on the nonce generated even if these are properly generated. We are only discussing here the case were the nonces are not properly generated and where a modulo bias allows to exploit them, but keep in mind that this is not the only threat depending on your threat model.
It is true in general that biases are “just” reducing the actual entropy of a randomly generated value and thus are not as dangerous as for the above schemes, but future cryptanalytic breakthroughs might exploit them. As such we definitively prefer to have uniformly distributed random values, plus they also usually allow us to really rely on the mathematical proofs of security, when we have one.
It is also interesting to note here that the only Wikipedia entry on the topic is found in the Fisher–Yates shuffle (aka Knuth shuffle) article, because this shuffle requires picking uniformly at random some indices during the shuffling. If you introduce a modulo bias there, you’ll end up with a biased shuffle… Which could be pretty bad for your e-voting solution, mixing network, or online lottery code, depending where you use that shuffle.
Avoiding the Modulo Bias
There are different methods to avoid Modulo Bias and obtain unbiased, uniformly distributed random integers.
The most common way: rejection sampling
Rejection sampling consists in sampling a random value and rejecting all values that do not fall into the right range. Typically, when your random value provider is providing random byte strings, you would sample a random value of the right byte size, cast it as an integer and compare it with the min and max values you want to sample from. If the random value falls within the correct range, you can keep it, otherwise you sample another random value, i.e. “rejecting” the random values that are not within the right range. The advantage of rejection sampling is that the distribution of the sampled values will remain uniform, provided the random values were uniform in the first place.
This can be achieved using our example Python script as follows:
import pandas
import os
values = []
while(len(values)<=1000000):
x = int.from_bytes(os.urandom(1), byteorder='little')
if x < 107:
values.append(x)
s = pandas.DataFrame({'value':values})

And you can directly see that the distribution looks uniform this time.
When doing rejection sampling, there are a couple cons that you need to be aware of: the larger your random value, the higher the risks of having multiple rejections before obtaining a valid candidate, obviously. But there is a trick to try and minimize the impact of this: you can, and you should “mask”, or “truncate” your random value to the bit size of the maximum value you’re willing to sample from. If you don’t, you’ll be sacrificing a lot of performance. But still, even if you do, there are “worst case” scenarios, where you’ll still be rejecting your randomly sampled value almost 50% of the time!
For example, if you are sampling something in the range ![[0, 2^{128}]](https://s0.wp.com/latex.php?latex=%5B0%2C+2%5E%7B128%7D%5D&bg=dddddd&fg=303030&s=0&c=20201002)
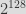

For instance, here’s how the Golang standard library is sampling a random integer between 0 inclusive and max exclusive, including all the above-mentioned methods as it can be found in the std lib in crypto/rand/util.go.:
// Int returns a uniform random value in [0, max). It panics if max <= 0.
func Int(rand io.Reader, max *big.Int) (n *big.Int, err error) {
if max.Sign() <= 0 {
panic("crypto/rand: argument to Int is <= 0")
}
n = new(big.Int)
n.Sub(max, n.SetUint64(1))
// bitLen is the maximum bit length needed to encode a value < max.
bitLen := n.BitLen()
if bitLen == 0 {
// the only valid result is 0
return
}
// k is the maximum byte length needed to encode a value < max.
k := (bitLen + 7) / 8
// b is the number of bits in the most significant byte of max-1.
b := uint(bitLen % 8)
if b == 0 {
b = 8
}
bytes := make([]byte, k)
for {
_, err = io.ReadFull(rand, bytes)
if err != nil {
return nil, err
}
// Clear bits in the first byte to increase the probability
// that the candidate is < max.
bytes[0] &= uint8(int(1<<b) - 1)
n.SetBytes(bytes)
if n.Cmp(max) < 0 {
return
}
}
}
In our example, the masking would reduce the random byte value to a random value on 7 bits, and would reject 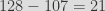
Using the modulo, but in a safe way
Surprisingly, there are ways to still rely on a modulo reduction to constrain our random values into a given range, without any risk of bias… But only for certain bounds!
As we discussed earlier, if you are generating a value between 0 and 106, using one byte of randomness, then you can combine both rejection sampling and modulo reduction to accept any value between 0 and 213 and then reduce it modulo 107, and this would still guarantee you a uniform distribution while significantly reducing the number of rejections, since you now have only 42 cases out of 256 possibilities where you reject, whereas you previously had 149 cases where you rejected with a “simple” rejection sampling. Notice that in the end, this is equivalent to the method using masking described above, because you are still rejecting the same proportion of random values (21 out of 128 in the first case, and 42 out of 256 here).
import pandas
import os
values = []
while(len(values)<=1000000):
x = int.from_bytes(os.urandom(1), byteorder='little')
if x < 214:
values.append(x % 107)
s = pandas.DataFrame({'value':values})
To give you an idea, here are the number of sampled values for each of the mentioned methods to obtain 1’000’000 random values :
| Method | Number of samples |
| Normal sampling (bias introduced) | 1’000’000 |
| Simple rejection sampling | 2’390’809 (+139%) |
| Rejection sampling and modulo reduction (or masking) | 1’196’604 (+19%) |
But actually modulo reduction will be fine in general as soon as the modulo you’re using is a divider of the max random value you can get. For example, if you are reducing a random x-bits value to a power of two that is smaller (i.e. a smaller bit-size). This works since you have a random value whose max value is 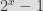



Rejection sampling combined with modulo works well, as long as you are very careful with your bounds, because otherwise you might have the same problem as Cryptocat, where they were doing rejection sampling from 0 to 250 inclusive before computing the modulo reduction by 10. This means that they had 251 possible random values instead of 250, and the 251th value, 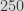
Okay, but I was mentioning ways to use the modulo in a safe manner, and actually it is worth noting here that when you have a number 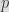


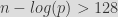
Conclusion
Alright, today we’ve seen what are modulo biases, that can be very dangerous for certain popular schemes and also how to avoid them. We have also seen that we really need to use rejection sampling whenever we need to generate uniformly at random a value within a given range, but that we can use some tricks to have as little as 1 rejected value on average when doing so.
Now, please be careful whenever you’re using the modulo in your favourite programming language, and ask yourself if you’re working on values that should be uniformly distributed or not.
Credits: Thanks to my colleague Nicolas for coming up with the Python code and figures illustrating this post.

Thank you for an informative article!